基本概念
- \(precision=TP/(TP+FP)\)。
- \(True Positive Rate (TPR)=recall=TP/(TP+FN)\)。
- \(False Positive Rate (FPR)=FP/(FP+TN)\)。
- ROC curve:横轴FPR,纵轴TPR,每个值是在某个分类threshold上对应的FPR和TPR的值。例如threshold为0,则全部样例都被归类为positive,没有样例归类为negative,因此FPR和TPR都是1。如果threshold为inf,则没有样例归为positive,因此FPR和TPR都是0。
- AUC:Area Under the ROC Curve。具体看wiki
- 信息量:假设\(X\)是一个离散型随机变量,其取值集合为\(\chi\),概率分布函数\(p(x)=Pr(X=x),x\in\chi\),则定义事件\(X=x_{0}\)的信息量为:\(I(x_0)=−\log(p(x_0))\)。直观理解:越不可能发生的事情,如果它发生了,信息量就越大。
-
熵:用来表示所有信息量的期望,即
\[H(X)=-\sum_{i=1}^{n}p(x_{i})\log(p(x_{i}))\] -
相对熵(KL散度):在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。
\[D_{KL}(p\vert\vert q)=\sum_{i=1}^{n}p(x_i)\log(\frac{p(x_i)}{q(x_i)})\]\(D_{KL}\)的值越小,表示q分布和p分布越接近
如何证明\(D_{KL}\)的值非负?看这里
相对于其他类型的函数距离度量,KL散度的优点在于,可以写成期望的形式,这允许我们对其进行采样计算即\(\mathbb{E}[x]\approx\frac{1}{n}\sum_{i=1}^{n}x_i,x_i\backsim p(x)\)
-
交叉熵:
\[H(p,q)=-\sum_{i=1}^{n}p(x_i)\log(q(x_i))=D_{KL}(p\vert\vert q)+H(p(x))\] - 最大似然估计和最大后验概率估计的区别
- 从最大似然到EM算法:一致的理解方式
待看
- 机器学习中正则化项L1和L2的直观理解
待看
各种技术
术语
- R-CNN: regional convolutional neural network
- FCN: fully convolutional networks
- RPN: region proposal network
- FPN: feature pyramid networks
Faster R-CNN
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- 从编程实现角度学习Faster R-CNN(附极简实现)
- 一文读懂Faster RCNN
- 图解Faster R-CNN简单流程
FCN
- Fully Convolutional Networks for Semantic Segmentation
- 精读深度学习论文(18) FCN - 清欢守护者的文章 - 知乎
- 深度学习论文笔记(六)— FCN 全连接网络
- 是用来做semantic segmentation而不是object detection或者instance segmantation的。通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。而要做Semantic Segmentation(语义分割),希望能够直接输出一幅分割图像结果,所以就有了本篇FCN网络的提出。FCN将传统CNN中最后的全连接层转化成1x1xC卷积层,然后用conv2d_transpose来上采样。由于没有全连接层的存在,所以输入图像的尺寸要求并不固定了。这个原因是因为全连接层是一个矩阵乘法的操作,可以自己去想一想。而最后实现的是对每个像素点的分类预测,而能做到这样,是因为卷积层的输出的结果是datamap,而不是一个向量!经过反卷积后得到与原图一样大小的1000层heatmap,每一层代表一个类,然后观察每个位置的像素,在哪一层它这个点对应的值最大,就认为这个像素点属于这一层的类
R-FCN
- R-FCN: Object Detection via Region-based Fully Convolutional Networks
- 论文笔记 R-FCN: Object Detection via Region-based Fully Convolutional Networks
- 深度学习目标检测模型全面综述:Faster R-CNN、R-FCN和SSD
- 比Faster R-CNN更快,但是能达到差不多(精度稍微差一点)的效果。怎么做到的:Faster R-CNN对卷积层做了共享,但是经过RoI pooling后,却没有共享,例如如果一副图片有500个region proposal,那么就得分别进行500次卷积,这样就太浪费时间了。R-FCN的思路是,能不能把RoI后面的几层建立共享卷积,只对一个feature map进行一次卷积。但与Faster R-CNN相同,其最后的输出是object的分类和BB回归。我的理解是,两者都用了海量anchor来propose ROI,不同的是Faster R-CNN在propose之后要对修正后的每个anchor单独做Roi Pooling和分类,而R-FCN不用再用一个单独分类网络而是直接用计算好的score maps来pool一下再加个softmax就搞定
- 目标检测-R-FCN-论文笔记 这篇文章写的非常好,特别是说明了为什么简单的直接在ResNet上(出来单个feature map)接一个FCN用来做检测的方案不work(文中图6和图2的对比)而需要用\(k^2\)组feature map(成为score maps)。最后那个R-CNN/Faster R-CNN/R-FCN的直观比较的图很赞。
U-Net
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- 和FCN类似,是用来做semantic segmentation而不是object detection或者instance segmantation的。
- 图像语义分割入门+FCN/U-Net网络解析:与FCN逐点相加不同,U-Net采用将特征在channel维度拼接在一起,形成更“厚”的特征。所以语义分割网络在特征融合时也有2种办法:
- FCN式的逐点相加,对应tensorflow的tf.add()
- U-Net式的channel维度拼接融合,对应tensorflow的tf.concat()
- 总结一下,CNN图像语义分割也就基本上是这个套路:
- 下采样+上采样:Convolution + Deconvolution/Resize(Resize指的是类似于keras的UpSampling2d,只是resize而不做deconvolution)
- 多尺度特征融合:特征逐点相加/特征channel维度拼接
- 获得像素级别的segement map:对每一个像素点进行判断类别
Transformer
- 各种降低attention复杂度的方法
ViT
GAN
- 互怼的艺术:从零直达WGAN-GP。关键在于,cross-entropy loss(KL距离或JS距离)在这里不能用,因为该loss是用来衡量两个概率分布的相似度的,因此需要在每个bucket上的概率作为输入,这对于一般的分类任务(只有O(10)个类别/bucket)没问题,但是对于生成的图片,即使是28x28黑白像素的生成的数字图片也会有\(2^{784}\)个bucket,不切实际而且很多bucket都是稀疏的(大部分情况下都是0或者都是1)。所以就自己搞了一个距离,用网络来学习这个距离,而关键在于判别器对距离函数所做的约束要使得:如果输入很相似则输出也很相似,即梯度很小(即导数值很小!!)。实现在这里
- 深度学习中的Lipschitz约束:泛化与生成模型
待看
- O-GAN:简单修改,让GAN的判别器变成一个编码器!
待看
- 从DCGAN到SELF-MOD:GAN的模型架构发展一览
待看
- AlphaTree:一张RoadMap,四个层次,十个方向百份源码,带你详细了解Gan发展历程
待看
- GAN介绍 - 生成式模型是如何工作的? GAN与其他模型有什么区别?
待看
Auto Encoder (AE)
- 自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(encoding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。
- 从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。
- 除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。
- 作为无监督学习模型,自动编码器还可以用于生成与训练样本不同的新数据,这样自动编码器(变分自动编码器,Variational Autoencoders)就是生成式模型。
- VQ-VAE的简明介绍:量子化自编码器 VQ-VAE其实跟VAE没什么关系,其实是一个AE
- 深入解析CogView、DALLE、VAE、GAN、GPT的技术原理,原来生成式模型是这么一回事! 先推导VAE再简化成VQ-VAE!所以VQ-VAE是从VAE推导出来的,虽然结果看上去跟VAE没什么关系(见下面的kexue文章)
- VQ-VAE解读解释了为什么要用PixelCNN/PixelRNN做decoder:
VAE的目的是训练完成后,丢掉encoder,在prior上直接采样,加上decoder就能生成。如果我们现在独立地采HxW个\(z\),然后查表得到维度为HxWxD的\(z_{q}(x)\),那么生成的图片在空间上的每块区域之间几乎就是独立的。因此我们需要让各个\(z\)之间有关系,因此用PixelCNN,对这些\(z\)建立一个autoregressive model:\(p(z_1,z_2,z_3,\cdots)=p(z_1)p(z_2\vert z_1)p(z_3\vert z_1,z_2)\cdots\),这样就可以进行ancestral sampling,得到一个互相之间有关联的HxW的整数矩阵;\(p(z_1,z_2,z_3,\cdots)\)这个联合概率即为我们想要的prior.
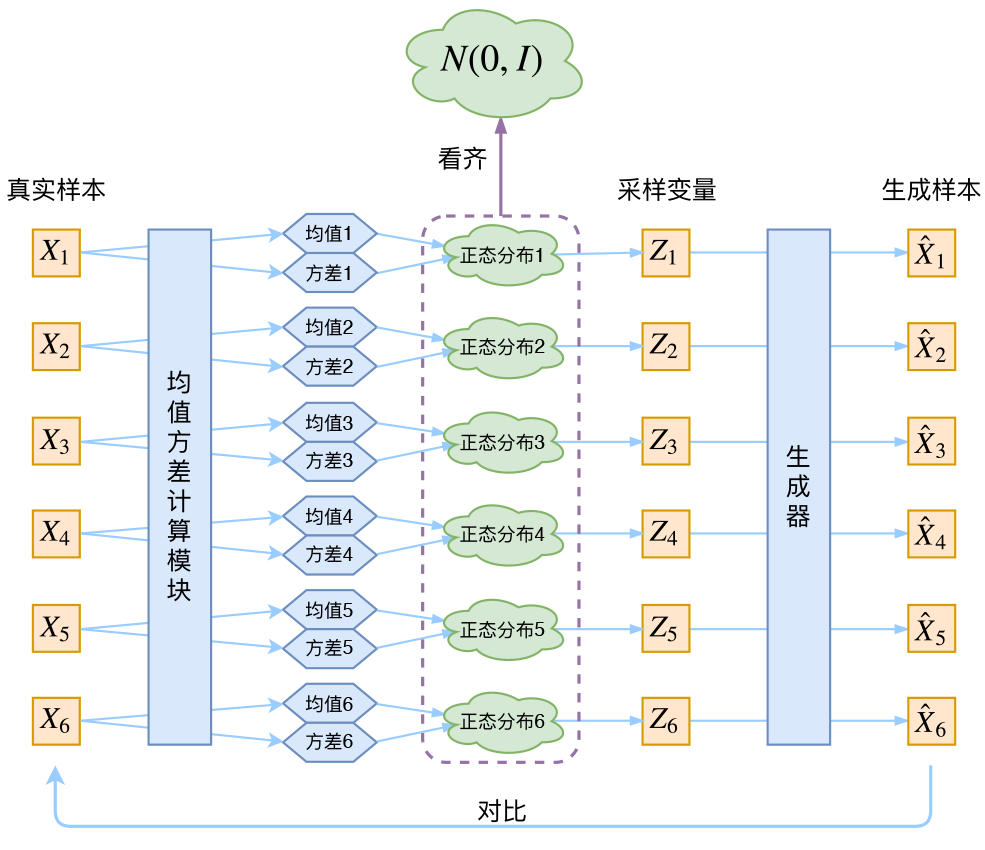
Variational Auto Encoder (VAE)
-
变分自编码器(一):原来是这么一回事。给定一个真实样本\(X_k\),我们假设存在一个专属于\(X_k\)的分布\(p(Z\vert X_k)\)(学名叫后验分布),并进一步假设这个分布是(独立的、多元的)正态分布。我们要训练一个生成器\(X=g(Z)\),希望能够把从分布\(p(Z\vert X_k)\)采样出来的一个\(Z_k\)还原为\(X_k\)。而正态分布\(p(Z\vert X_k)\)有两参数(均值&方差),我们用神经网络把它们拟合出来,然后从这个专属分布中采样一个\(Z_k\)然后生成\(\hat{X_k}=g(Z_k)\),然后最小化它和\(X_k\)之间的距离。而为了不让改正态分布退化成一个点(随着距离的最小化这是一种必然趋势),VAE还让所有的\(p(Z\vert X)\)都向标准正态分布看齐,这样就防止了噪声为零,同时保证了模型具有生成能力。重构(采样)的过程是希望没噪声的,而向标准正态分布看齐得到的KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。代码在这里
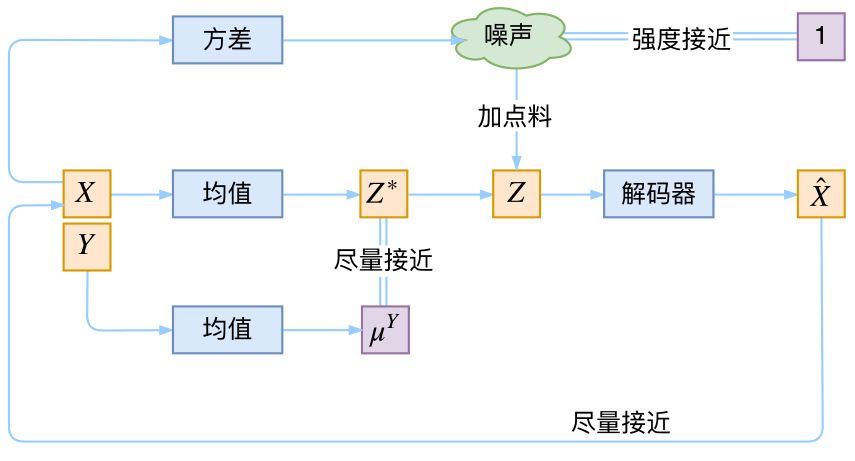
除了向标准正态分布看齐,如果给定每个类别的均值,我们还可以让其向每个类别的正态分布看齐(方差还是1),这样就是Conditional VAE,或者叫CVAE。
- 变分自编码器(二):从贝叶斯观点出发。进行了完整的推导。
简单来说,由于直接描述复杂分布是难以做到的,所以我们通过引入隐变量来将它变成条件分布的叠加。而这时候我们对隐变量的分布和条件分布都可以做适当的简化(比如都假设为正态分布),并且在条件分布的参数可以跟深度学习模型结合起来(用深度学习来算隐变量的参数)
- 变分自编码器(三):这样做为什么能成?
未看
- 破解VAE的迷思认为:
VAE的任务:要学的图像是高维空间中一些离散的点,VAE试图把它们压缩到一个低维连续空间(也就是潜空间),再复原回原空间。这么做是基于这样的假设 - 那就是要学习的实际上是嵌入高维空间的低维流形,然而真实图形中的细节显然不全是某种低维流形,有些图像细节,比如处于空间中的头发,肤质,真实纹理质感,即使是某种流形,也很难用低数据量描述,或很难学得用低数据量描述。考虑到其他深度网络都是使用一个过容量(表示容量)的网络来学习一个简单平滑的函数,VAE使用一个瓶颈式的潜空间向量去实现前述任务就显得不太现实了。因此,VAE无法还原图像的细节,看上去缺乏真实感,同时,在不能还原的前提下,为了降低损失,只有输出平均值,对于人脸来说,就是生成一张大众脸。如果潜空间向量使用比较低的维数,原图中的人脸即使被遮挡了,还原图像也会生成被遮挡的部分,因为大多数训练样本是一张完整的脸。如果使用比较大的潜空间向量维数,还原质量会好一些,也不会出现人脸自动去遮挡的效果,但是采样质量较差。因为潜空间变大了,高维空间的离散点映射过来,不再容易保证连续性。
- 深度神经网络生成模型:从GAN VAE到CVAE-GAN 把vae和gan结合起来,生成质量非常高。但上述文章说它只是假装解决了生成图片模糊的问题:
CVAE-GAN假装解决了这一难题,它可以在一个细粒度分类中生成高质量的图像。比如在训练后,可以生成某一个人的人脸,但实际上它是通过让网络学习某个人的很多张照片来记住这个人的模样。它不是通过潜变量来传递这个人的相貌信息,而是通过一个单独的flag(即那个分类c)告诉后面的生成网络,请生成这个人的脸。
- VAE的哲学,GAN的哲学对两者的本质的一些思考
- 强大的NVAE:以后再也不能说VAE生成的图像模糊了 2020 nvidia的工作,更厉害。
待看
- VAE 的细节:p(x|z)的噪音,与p(z|x) 的编码坍塌有一些简单的例子来说明VAE的问题
待看
- 参考:
- Understanding VQ-VAE (DALL-E Explained Pt. 1) 提供了VAE非常好的high-level的推导。
- Latent spaces are compressed representations of data, which often emphasize the most important and semantically interesting features of the data in their representation.
- A learned latent representation can be useful for many downstream algorithms.
- Autoencoders are a method for finding latent spaces that are complicated non-linear functions of the data.
- Variational autoencoders add a prior to the autoencoder latent space. This gives the learned latent space some very nice properties (i.e. we can smoothly interpolate the data distribution through the latents).
- How is it so good ? (DALL-E Explained Pt. 2)
待看
- 快速推导 VAE 变分自编码器,多种写法,和重要细节 Variational Autoencoder
待看
- 解耦表征学习 - 变分自编码器解读 (Variational Autoencoder, VAE)
待看
- Tutorial - What is a variational autoencoder?
待看
- Understanding VQ-VAE (DALL-E Explained Pt. 1) 提供了VAE非常好的high-level的推导。
流模型
- 细水长flow之NICE:流模型的基本概念与实现 和VAE(通过关于凸函数即似然函数里的log的Jensen不等式优化下界)以及GAN(通过交替训练的方法绕开求积分)不同,flow模型选择了一条“硬路”:使用狄拉克分布直接把积分算出来,而这样做要满足很多条件,于是flow就自定义了很多种网络结构来满足这些条件,很多层这些网络连起来就形成一个“flow”。
半监督学习(Semi-Supervised Learning)
- 是监督学习和无监督学习的结合:use both labeled and unlabeled data at the same time to improve the performance of a supervised model
- FixMatch用无label的图片来提升模型性能。有两个loss,一个是对有label的数据做简单的分类任务的loss;另一个是对无label的数据先做weak augmentation然后跑一遍model得到一个预测,如果预测对某个类的概率比其他类的概率大于某个阈值,就用最高概率那个类作为pseudo label,然后对无label的数据做strong augmentation跑一遍model得到的预测结果和该pseudo label来得到该loss。两个loss加起来作为总的loss。
- 这有点像one-shot learning?
自监督学习(Self-Supervised Learning)
- 根据StackExchange:这可以看成是半监督学习的一种(learn image representations without requiring human-annotated labels and then use those learned representations on some downstream tasks)
- The Illustrated Self-Supervised Learning。常用的学习方法:
- image reconstruction
- colorization:将图片去色,让模型学习填色
- superresolution:将图片缩小,学习还原原来的分辨率
- impainting:即图像补全:将图片挖去一块,学习补全
- cross-channel prediction: predict one channel of the image from the other channel and combine them to reconstruct the original image
- common sense tasks
- image jigsaw puzzle: 把图像切成多片,学习一个permutation number来将这些碎片拼回去
- context prediction: 将图片切片,选择其中一片以及其相邻8片中的一片,学习该相邻的片究竟是相邻的哪一片
- geometric transformation recognition: 随机旋转图片(90度的倍数),预测旋转的角度
- automatic label generation
- image clustering: 输入为图片及其类别(这样的data很容易找到,例如对于“海滩”类图片,网上一搜一大堆),该类别作为label来train
- synthetic imagery: 用3D游戏引擎生成图片及其对应的参数(例如轮廓、深度等信息)作为training data
- frame order verification: 从视频中得到每一帧的图像,学习这些帧的顺序(例如帧A是否出现在帧B之前)
- image reconstruction
-
SimCLR是一种contrastive learining,是self supervised learning的一个特例。输入是一个batch的图片,对其中每个图片做augmentation生成两个图片,目标就是最大化同一个图片生成的两个augmentation的相似性,并且最小化不同图片生成的两个augmentation的相似性。相似性\(s_{i,j}\)用余弦来衡量,对任意一个(augmentation的)图片,其Noise Contrastive Estimation(NCE)Loss为:
\[l(i,j)=-\log\frac{e^{s_{i,j}}}{\sum_{k=1}^{2N}e^{s_{i,k[k\ne j]}}}\]其中\(N\)为batch中图片的个数。最终的loss为:
\[L=\frac{1}{2N}\sum_{k=1}^{N}\left(l(2k-1,2k)+l(2k,2k-1)\right)\]
对比学习
- 一文梳理无监督对比学习(MoCo/SimCLR/SwAV/BYOL/SimSiam)。问:
为什么MoCo的双塔要用不同的参数?为什么不用一样的参数?是由于memory bank吗(重新算一次bank里的所有负例的表示太expensive?)?而SimCLR貌似只用了一个encoder(share weights)。
- 无监督对比学习之MOCO
为啥这么搞呢?在优化的过程中,如果key的encoder剧烈变化,key的特征也随着发生较大变化。query的encoder也在训练初期是在剧烈变化,而query的特征在softmax的分子,key在分母,当softmax的分子和分母均有巨大变化的时候,对于无监督的优化可能不是那么友好。因此MoCo限制了key的encoder的剧烈变化,相当于分母项的扰动少了,有助于query的encoder的更新。
- SimSiam探索孪生神经网络:请停止你的梯度传递!
后半段没看太懂
- Understanding self-supervised and contrastive learning with “Bootstrap Your Own Latent” (BYOL)
- 译文在自监督学习BYOL中魔鬼BN
没看
- 译文在自监督学习BYOL中魔鬼BN
- 如何评价Deepmind自监督新作BYOL?
很多干货,没看
Few-shot / Zero-shot learning
- 小样本或零样本学习,对于语言模型来说,基本上就是把要预测的结果转化为完形填空,让语言模型去填(MLM)。
- 必须要GPT3吗?不,BERT的MLM模型也能小样本学习
假如给定句子“这趟北京之旅我感觉很不错。”,那么我们补充个描述,构建如下的完形填空:“____满意。这趟北京之旅我感觉很不错。” 进一步地,我们限制空位处只能填一个“很”或“不”,问题就很清晰了,就是要我们根据上下文一致性判断是否满意,如果“很”的概率大于“不”的概率,说明是正面情感倾向,否则就是负面的,这样我们就将情感分类问题转换为一个完形填空问题了,它可以用MLM模型给出预测结果,而MLM模型的训练可以不需要监督数据,因此理论上这能够实现零样本学习了。
- 必须要GPT3吗?不,BERT的MLM模型也能小样本学习
Reparameterization
- 函数光滑化杂谈:不可导函数的可导逼近
待看
- 漫谈重参数:从正态分布到Gumbel Softmax 文章谈了为什么要进行重参数以及对离散和连续分布的重参数方法。另外重参数不一定是只对loss有用,有时候遇到一些不可导或者采样的方差很大的函数也需要重参。
如何理解直接采样没有梯度而重参数之后就有梯度呢?其实很简单,比如我说从\(\mathcal{N}(z;\mu_{\theta},\sigma_{\theta}^{2})\)中采样一个数来,然后你跟我说采样到5,我完全看不出5跟\(\theta\)有什么关系呀(求梯度只能为0);但是如果先从\(\mathcal{N}(\epsilon;0,1)\)中采样一个数比如0.2,然后计算\(\),这样我就知道采样出来的结果跟\(\theta\)的关系了(能求出有效的梯度)。
各种技术的融合
- VQ-GAN
- DALL-E
- CLIP
- Alien Dreams: An Emerging Art Scene展示了如何通过GAN+CLIP来用文字生成图片。这是一个迭代过程:首先生成一个随机latent vector,用GAN生成图片,然后用CLIP和输入的文字做相似度比较,对loss生成梯度来更新那个latent vector。这样就可以生成一个video了。
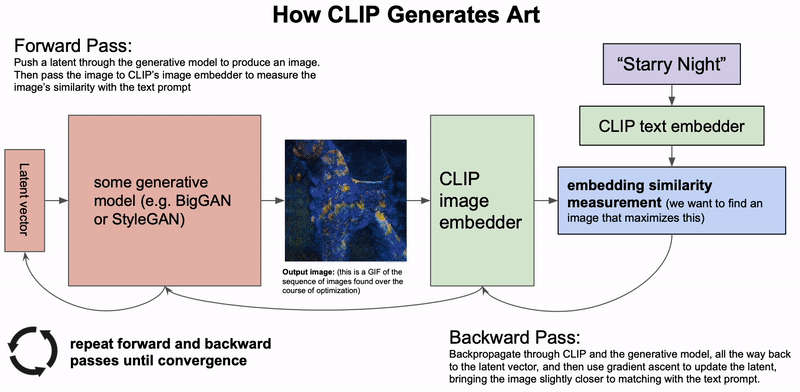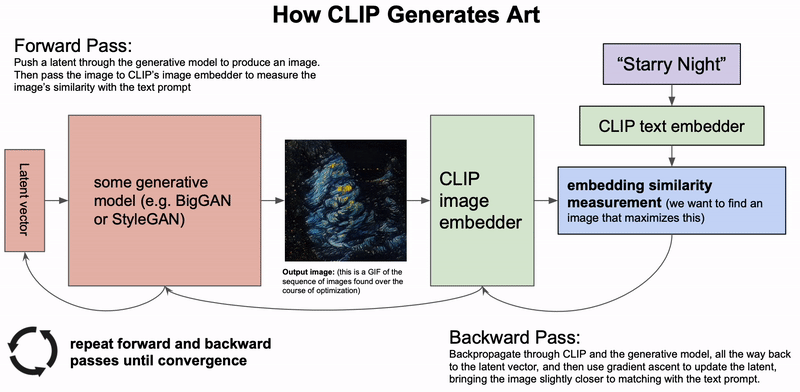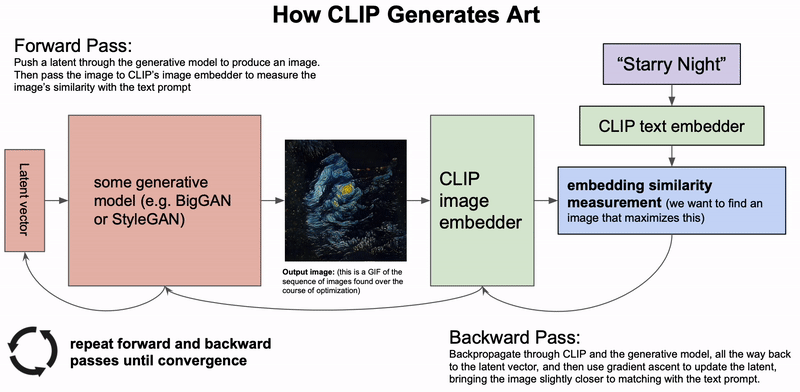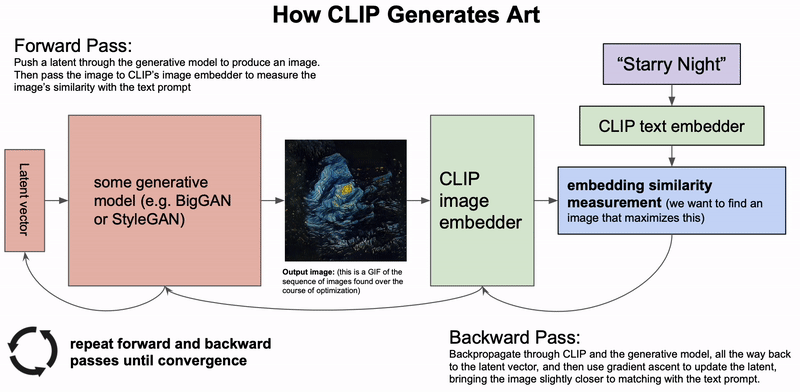
思考:是否所有视频都可以表示为梯度下降的过程?例如某个物体从状态1(位置,方位等)变换为状态2,可以看成:把该物体的状态encode成一个latent feature,然后让状态1(source)和状态2(target)的latent feature计算相似性然后算出loss,那么这个变换过程就是梯度下降(减少loss)的过程。
- Alien Dreams: An Emerging Art Scene展示了如何通过GAN+CLIP来用文字生成图片。这是一个迭代过程:首先生成一个随机latent vector,用GAN生成图片,然后用CLIP和输入的文字做相似度比较,对loss生成梯度来更新那个latent vector。这样就可以生成一个video了。
Speech
- 语音识别技术的前世今生里面对transducer的解释(建立了输出的语言模型)非常形象易懂,对其与attention的区别的描述也很形象(被动等待下一个有意义的CTC输出 vs 主动根据输入找寻下一个输出)!
- 自监督预训练(二) 语音部分
- 自监督预训练(三)wav2vec 2.0原理剖析
- wav2vec 2.0 | Lecture 76 (Part 3) | Applied Deep Learning讲的很清楚,最神奇的地方是,model中并没有重建原来语音的部分,而只是重建了latent feature
为什么这样也能学习到语音的特征?可能是因为预测那些mask掉的部分的时候就是需要知道语音特征,而连续的语音特征之间是满足某种条件分布的,因而不是随机的!
- 注意其中transformer的输入不是quantized的而是连续的,但是做contrastive loss的target是要跟quantized的feature来比较。文中详细比较了{quantize vs 不quantize}{input vs target}四种情况发现上述方式最好
为什么?
- 注意其中transformer的输入不是quantized的而是连续的,但是做contrastive loss的target是要跟quantized的feature来比较。文中详细比较了{quantize vs 不quantize}{input vs target}四种情况发现上述方式最好
- wav2vec 2.0讲解
其他
一些理解
计算机视觉
- 拿灰度图像来说,如果用0-255来编码一个灰度图像,很自然我们用0表示黑255表示白,数值越大越接近白,越小越接近黑
- 为什么不能吧顺序打乱?例如0表示浅灰,100表示白,200表示黑,255表示深灰色等等?
- 原因是这种编码表示必须满足一个特性:如果我们肉眼看到两个灰度很接近,那么这两个灰度在编码上的表示也应该很“接近”
- 怎么定义“接近”?这里用的是差值:差值越小越相似
- 那我可不可以用其他相似性定义?我觉得可以,只要这种定义满足线性关系(例如a和b比a和c更相似,那么a和b的相似性的数学表示应该在值上和a和c的相似值满足某种全序关系。问:可以是偏序吗?)但是除了正常的线性编码外(例如0表示黑255表示白或者反过来),这样的相似性定义应该很难找
- 而两个图像相似是一个至少是一个三元关系:颜色相似、形状相似且大小相似。所以我对视觉计算的理解就是如何定义、计算并处理这些相似性。
- 这就决定了为什么convolution用的是乘法和加法:待续。。。
一般理论
- 一般的模型都可以分成几类
- 判别模型(encoder)。例如用于分类的模型、BERT、object detection等。
- 生成模型(decoder)。例如GPT等。
- 判别模型+生成模型。如GAN是生成器后接判别器,AE和seq2seq是encoder后加decoder,等。
LLM与通用人工智能
- 盗火后的世界—人类、AI和法律的未来寓言
- 李航尽管认为GPT尚不具备基于三段论的逻辑推理(logical reasoning)能力,也认为已经具有类推推理(analogical reasoning)
- 几乎所有科学家都不坚持机器人要像人一样思考才能获得智,并明确提出“发现机器智能最重要的是能够解决人脑所能够解决的问题,而不在于是否是需要采用和人一样的方法”。沿着这条思路很容易发现如果人类学习鸟类并不是为了拍翅膀,而是要飞行。而最终人类飞上蓝天靠的也的确不是扇翅,而是靠固定翼、旋翼飞行器和动力火箭。图灵奖得主Edsger W. Dijkstra早期曾认为计算机会不会思考这个问题,就像问潜水艇会不会游泳一样,这使得很多人认为AI不会思考而只是表现得像思考。但既然蛙泳自由泳仰泳以及狗爬都算游泳,为什么潜水艇就不算游泳?换句话说,潜水艇会不会游泳都没关系,能潜水和操控移动就足够了。如同不能以鸟类来评价飞机,用人类尺寸丈量计算机、以人类思维去评价AI也很可能是错位的。
- 我的看法:我一直尝试证明LLM不过是一个非常复杂的概率模型,不过是按照某种复杂的逻辑来预测下一个token,但是进一步思考会发现,人脑又有什么不同呢?进而我得出一个貌似比较极端的推论,我目前还没办法推翻:不管什么样的智能,都是基于对现实世界各个对象的关系进行学习。例如,逻辑关系也是一种关系。LLM如果能对某种关系进行建模,就能模拟出人类对应对智能。
Convolutional Neural Networks (by Andrew Ng)
- 视频链接在这里
- 例子:边缘检测:通过用conv2d并设置特定的filter/kernel的值可以用该filter/kernel做边缘检测(横的或者竖的或者斜的或其他)
- LeNet:最原始用于手写数字识别的网络,只有几层
- AlexNet: Hinton等人发明的识别一般图像的网络,有大约十来层?感觉每一层都是hand-tuned的
- VGG-16:避免hand-tuned:统一采用相同规格的block例如3x3的conv2d,证明也能达到好的效果
- ResNet: 增加了short-cut,可以使网络通过学习自动选取究竟是否应用新的一层。例如如果新的层会导致精度更差,训练过程能够学习到这个结果从而通过自动调参来增大short-cut的权重从而降低其认为影响了精度的block的权重(让该block变为大约相当于identity的功能,从而大程度上禁止了该block的功能)。而普通的deep network没有这种选择所以有可能会在很deep的时候反而精度更差。
- Inception: 与其决定每个block用1x1conv还是3x3conv还是别的,干脆全都用然后将结果concat起来作为下一层输入。block内用到的层有:1x1conv+3x3conv,1x1conv+5x5conv,1x1conv,maxpool等。
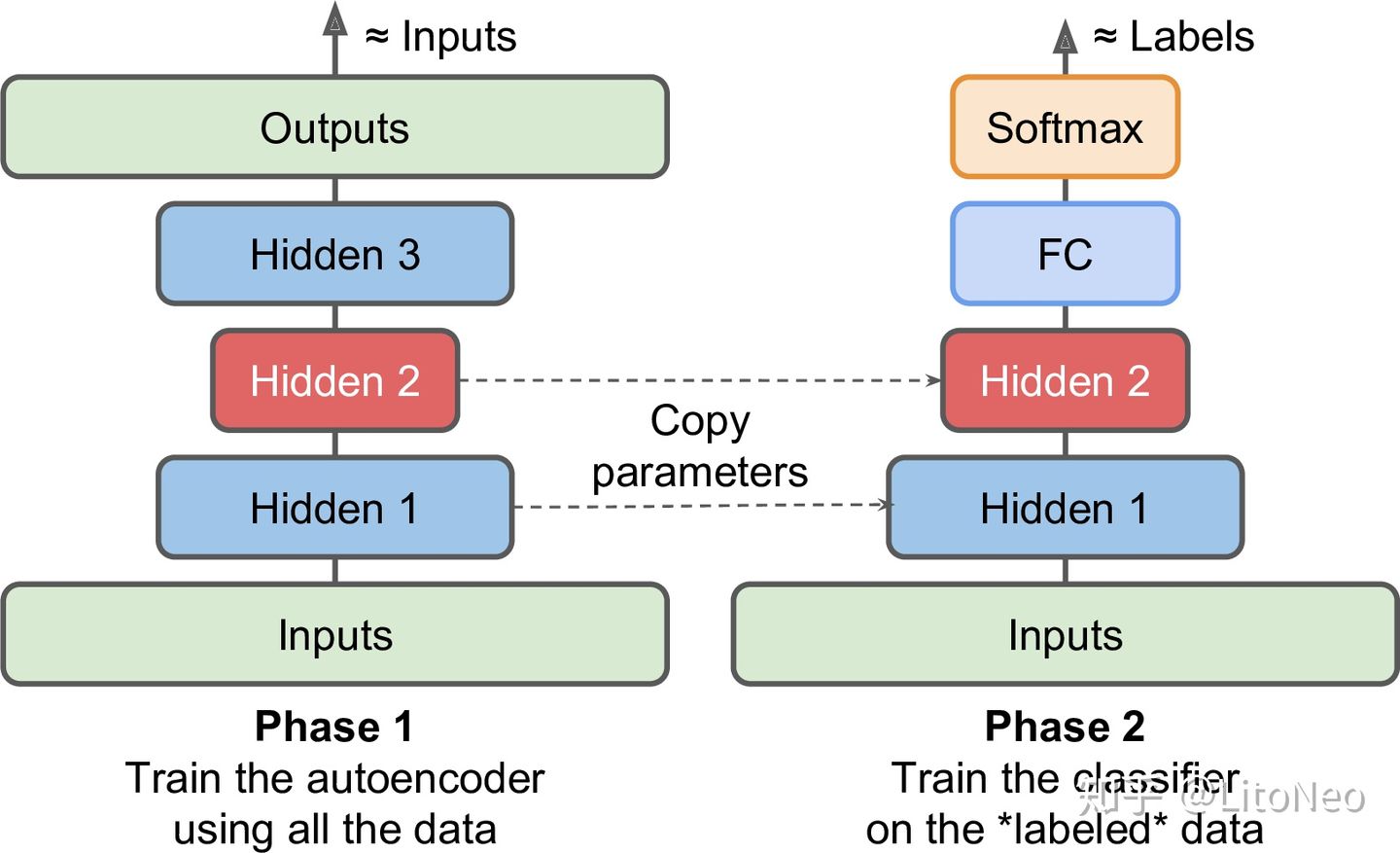
- Transfer learning
- 可以下载已经train好的如ResNet50的model,然后把最后的softmax层替换掉,将其他层的参数freeze,只重新train最后softmax层的参数(用新的数据)
- 或者可以任意选择freeze前面N层而只重新train后面那些层(当然还是要先把softmax换为适合新应用的类别个数的softmax)
- 可以预处理:把所有新数据的前N层的结果预先求出,避免之后重复计算
- 数据预处理/增强技术:mirroring,random cropping,rotation,color shifting,等
- Object Detection
- 基本思想:slicing window
- 如何避免真正的slicing window并为每个window算一遍是否里面有某个object:直接用conv处理原图,filter的strides设为slicing window的stride
- anchor boxes和Yolo algorithm:没太懂?
- R-CNN vs. Fast R-CNN vs. Faster R-CNN
- 人脸识别
- Triplet loss:每次的输入是一个triple:一个人脸图,一个和第一个图是同一个人的人脸图,一个其他人的人脸图。目标是最大化(前两图的相似性-第一和第三张图的相似性)。缺点是:需要显式定义相似性度量函数例如用余弦相似性,而这很可能不是最好的度量
- 另一种种方法是,把相似性度量改为一个network module(黑箱)而让其输出0(不是同一个人)或1(是同一个人),这样能学习到好的但不能显式表示的度量函数。再一次,这里可以通过freeze整个network的前大半部分,而precompute特征向量,只train这个黑箱,来加速网络的训练
- Neural Style Transfer
- 如何visualize一个conv net的每一层到底detect了什么:可以选出使该层的某些activation unit的值达到最大值的输入图片来get some sense
- Neural Style Transfer的关键就是定义一个cost function,由两部分组成:content cost和style cost。content cost评价结果图片和content image的“相似”程度,style cost评价结果哦图片和style image的style的“相似”程度。
- 计算这两种cost的方法都是:选择某个层,对content/style input image和结果图片分别计算该层的输出,然后在该层上定义content/style的相似性,然后对所有层的content/style相似性加权求和便得到最终的content/style相似性。唯一的区别是content/style的相似性的定义:对于content相似性直接用对应层的值求差和平方和即可,对于style相似性要先计算该层上C个channel间的correlation得到一个CxC的矩阵然后再用两个图片的这个矩阵求差和平方和得到(为啥是这样呢?correlation可以这样理解:correlate的意思是,对应于两个不同channel的两个特征要么同时出现要么同时不出现)
- 对于每层在最终相似性中的权重,可以通过第一步的visualization得到一些sense。